| © 2022 Black Swan Telecom Journal | • | protecting and growing a robust communications business | • a service of | |
| |
| Email a colleague |
October 2020
Mobileum Tackles Subscription Fraud and ID Spoofing with Machine Learning that is Explainable

“The beginning of wisdom is to call things by their proper names.”
Confucius, The Analects
The proper naming and classifying of telecom fraud is the first step to gaining fraud-fighting wisdom. It’s especially crucial considering the hundreds of different national languages/cultures that make up global telecom.
Taking on this tough task of classifying and quantifying telecom fraud is the purpose of the Global Fraud Loss Survey, a biennial project of the Communications Fraud Control Association (CFCA).
Top-notch fraud experts from around the world are behind this Survey. Many hail from Tier 1 retail and wholesale operators. However the Survey also estimates the impact of fraud on operators of all sizes across mobile, fixed, and OTT sectors.
The Survey makes a key distinction between Fraud Methods and Types of Fraud Losses. For example, International Revenue Share Fraud (IRSF) is a Type of fraud loss, but there are many Methods or paths to an IRSF crime, such a PBX hack, Wangiri Call-back scheme, or Mobile Malware that turns a mobile phone into a traffic pumping device.
I grouped the 2019 Fraud Loss Survey’s Methods in a summary chart:

Now let’s look at Subscription Fraud, the subject of this story. In the chart below, I’ve grouped three kinds of Subscription Fraud with two related fraud methods as follows:
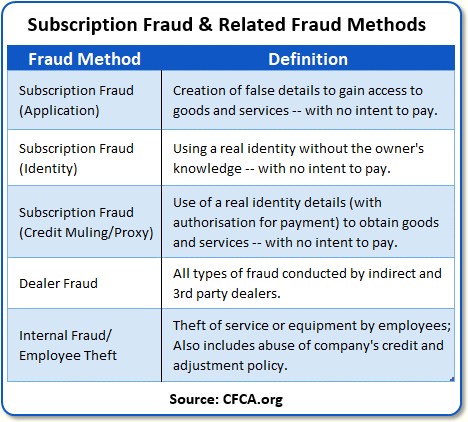
Grouping Dealer Fraud and Internal Fraud/Employee Theft with Subscription Frauds made sense to me since a Subscription Fraud system can be used to discover many kinds of dealer and internal frauds — though certainly not all.
Well, with CFCA’s Survey definitions setting the stage, let’s now turn to an excellent overview of the Subscription Fraud problem given by Carlos Martins, the Cloud and AI Senior Product Owner at Mobileum.
The analysis Carlos gives is the best tutorial I’ve seen on Subscription Fraud. He covers: the key vectors of the Fraud, the parties who commit the fraud, the need for a multi-database approach, the great precision required to screen names and addresses, and — last but not least — an informative discussion of Machine Learning/AI’s key role in Subscription Fraud.
| Dan Baker, Editor, Black Swan Telecom Journal: Carlos, we know the subscription and ID fraud threats are coming from a lot of different directions. What’s your assessment of the threat environment? |
Carlos Martins: Dan, I think the word “pandemic” is an accurate description for what we’re seeing today.
The most obvious change is the Covid 19 storm. Businesses around the world are facing big impact — lower sales, cash flow, and revenues dropping. Fraudsters are trying to take advantage of the confusion by stepping up their game.
Now from a telco standpoint, one positive aspect of Covid 19 has been to push the need for better communications to the home, including telecommuting.
But on the flipside, today’s greater reliance on on-line sales instead of in-store purchase of mobile phones and services is forcing telecoms to shift more and more of their business through the digital sales channel, which increases the pressure on having solid subscription fraud controls in place.
And yes, the threats are everywhere. Here are some of the most important fraud vectors:
- Mobile apps are often free, but some are offered merely to collect data
on the user to sell that intelligence to third parties to compromise the user’s
identity, such as taking over a user account.
- Hyperlinked SMS messages set the stage for pharming, directing
the user to a bogus website that mimic the appearance of a legitimate one.
The identity or logo of well-known companies or a government organization may
be spoofed such as that of the IRS (the Internal Revenue Service (taxing authority
of the US government).
- Excel files are a risk because automated macro routines inside can gain
access to information on your PC, enabling ID information to be stolen.
- Ransomware locks users out of their PCs and even mobile devices.
The fraudsters blackmail the user, then return control of the device when the
ransom money is paid.
- iCloud users were compromised by a phishing attack. Text messages
invited the user to login to a fake iCloud webpage. The fraudster gained
access to key ID information of the user. Other text messages have
been linked to two-factor authentication scams.
- Wangiri call backs to bogus international premium rate numbers are initiated
by a SMS invitation to call.

- Banking phishing attacks often say a bank account is compromised and
invites the user to reset the password on a fake bank webpage.
- Free subscriptions are even a problem because it’s common practice
for people to use the same password for many different accounts. So if
a fraudster has access to one password, they will try to reuse that password
on other accounts.
In general, wherever privacy is at risk, the customer’s identity is also at risk. You detect an identity problem when the customer behaves differently, but it’s an enormous technical challenge to separate what is normal from what is abnormal.
At this stage, telecom fraud analysts face some very big headaches in the subscription fraud area.
| Who are the fraudsters committing subscription and ID spoofing fraud? |
Well, the classic definition of subscription fraudster is anyone who uses or steals an identity and has no intention of paying for the device or telecom service they bought on credit.
Over the years, this has become a very lucrative market for the fraudsters. The perpetrators of subscription fraud fall into these groups:
- Subscribers themselves are the first subscription fraud culprits.
If they obtain devices or services with no intent to pay, they are as guilty
of fraud as any third party. Yes, a subscriber may run into financial
trouble and become a collections case. But the subs who simply won’t pay are entirely different.
- Hackers are experts at various technical means of gaining ID information
such as conducting phishing attacks or cracking signaling, applications and
login webpages. Hackers are often paid by criminals who actually perform
the frauds.

- Mules are people trying to make easy money. They use their real
ID to sign up, say, for a mobile subscription contract to get sent a device
or get access to a telecom service. Then they sell it to a third party
fraudster. Students are often targets to act as mules, destroying their
good credit when they help a fraudster.
- Crime organizations are emboldened by numerous opportunities to compromise
accounts via phishing, mobile device attacks, and other ID capturing schemes.
They will orchestrate scenarios using mules and even subscribers they are friendly
with. Last year the Europol arrested 400 criminals. The investigations
revealed an organization doing 12 million Euros of fraud a year.
- Dealers and Agents are in a good position to commit fraud because they
know how the telecom business works and its vulnerable points. The dealer
can earn a commission by simulating false services or equipment sales.
- Operator employees, sadly, are another key source of subscription and
ID fraud. Those employees in IT or network functions are in a particularly
good position to rig systems to enable fraud. Family members and friends
of employees can also help perpetrate the fraud.
| What are some of the methods used to detect subscription fraud control? And what constitutes a subscription fraud control system? |
Dan, any subscription fraud system is a highly automated investigative tool. The best systems are powered by machine learning, which I’ll discuss shortly. Since there are so many entry points to subscription fraud, the idea is to connect to a wide array of data sources, then analyze those combined sources to solve a particular problem.
So a subscription fraud control system is used to audit many things, for instance:
- Asset acquisitions — Identifying people buying equipment or services on credit with no intention to pay.
- IRSF & Premium Rate Services — If a mobile phone is being used to commit IRSF fraud, that prompts a broader investigation to check if that mobile fraud was enabled by an ID spoofing or subscription fraud.
Let me walk you through some important subscription fraud use cases and techniques you and your readers should get to know:
Account Theft
Fraudsters with no intention to pay are busy building new accounts. So leaked personal ID information they find on a website can be used by a hacker to try to log-in and pretend to buy a new device or service.
Here, your system must keep track of past addresses so if someone tries to have you send something to a false address, you immediately know the address is not reliable.
For log-ins, it’s advisable to keep track of different log-in locations. And if a log-in occurs from a new location, you should be ready to notify your systems that this is probably an account theft.
Likewise, if information has leaked about an account in the last 48 hours, and suddenly that account is buying a device and the delivery address is different from normal, you should log it and ask the customer to come to a store to do that purchase.
The point is to correlate all these bits and bytes from different data sources so you can be very defensive.
Cash Flow Fraud by Dealers
A wealth of information is contained in the transactions being executed by your dealers.
If you see an unusually high volume of activations at the end of the month, that could indicate a problem.
For example, we know that commission payments are a good way for a dealer to get better cash flow. So if a dealer has a lot of activations at the end of month but at the start of month there are a lot of order reversals, then it may be that the dealer is calling on his friends and family to make fictitious purchases.
In this way, they will be able to return the money later on and use the cash flow to help themselves.
Abnormal Contract Behavior
Normally, a person will buy a mobile phone in the town where they live. So it’s important that you map the distance to make sure the distance is normal for the person.
Also, fraudsters tend to take advantage of process delays in provisioning the service. So maybe a customer gets a twenty-four month contract for telecom service but suddenly he does a reversal, then an upgrade, then another reversal.
Sometimes the systems don’t have access to the latest data available on the status of the subscription. This allows agents and dealers to take advantage of these lag times and lack of real-time integration.
Credits Notes to a Customer Account
How strongly audited are credit notes to an account? It’s highly unusual for one customer to be given multiple credits for free service usage.
To identify credit problems, you need to make sure you have a working device and a working platform to identify recurrence of suspicious patterns. The system will learn normal credit note behaviors and raise an alert if it looks like there’s abuse.
In general, money flows are complex and hard to follow, so AI can prove very useful here. What’s more, the people who can commit fraud on your system are those who know your systems and are familiar with its weak points.
If the internal fraudster coordinates his fraud with the people who approve credit notes, then they gain a far easier path to fraud.
| OK, let’s talk about Mobileum’s approach to the subscription fraud problem with Machine Learning. How does ML add value in the identity spoofing/subscription fraud space? |
Well, let me first give you Mobileum’s approach to implementing ML/AI, Dan. We are one of the early adopters of ML in the telecom risk management and roaming space, and having that experience means we know what it takes to deliver ML successfully for clients.
To begin, all Machine Learning (ML) models are built with training data, usually historical data. And the outcomes of historical data are identified and labeled by a human expert.
That is what’s called a supervised ML model. And it’s great because it makes it easier to get started with ML. However, to use a fully supervised approach requires the data to be available in a compatible structure which often is not the case.
The other approach is to use unsupervised machine learning models that use the data that exists and applies algorithms on top of that data.
Mobileum believes in a hybrid approach to ML training, taking the best of supervised and unsupervised learning. You start with unsupervised, using deep learning models. At the same time, users are classifying data. So after a few months, the system is already providing answers based on the classifications.
Anomaly detection plays a key role in learning. It tries to identify what’s normal and not normal — and it will notify you anytime something goes beyond what is happening in your subscriptions.
| With subscription fraud, there are dozens of use cases. So how does Mobileum apply ML to manage all these different use cases in one system? |
When you build a model — either supervised or unsupervised — it needs to be built in a way where a human can understand how a decision was made.
This an important principle whenever Mobileum builds an AI or ML solution: we ensure every decision made by the AI engine is explainable. The danger is, when ML decisions are not explainable, it’s as if the ML is operating as a black box and the users lose confidence in it.
For example, if you are presenting an outlier in the data, you cannot just show a percentage. You need to explain to the end user exactly why it is an outlier.
The beauty of explainable AI is you always know the key features the models are using, and you can read a simple sentence explaining why machine learning made a certain decision.
With AI, the creation of rules is largely replaced by the engineering of features.
Features are nothing more than a set of input variables related to trends in the historical data. For instance, if your model is trying to predict traffic volumes for a given day, a feature might be an average of historic traffic on a particular day — or it might weekday or weekend historic traffic.
Generally, an ML model will use as many features as are available and correlate them in a way that makes sense of the data. You train the models by providing it a set of features: “OK, for this kind of analysis, the relevant features to use are X, Y, and Z.”
And the assignment of features needs to be pretty dynamic because a feature that’s important today may not be important tomorrow. This dynamism in maintaining the models is a key capability to have in ML.
A key design rule-of-thumb is: don’t rely on any preconceived way your business is flowing. Instead, let the system learn from the data and make sure you can present the analysis in an explainable way so users have confidence in it.
| One of the concerns people have with Machine Learning is that humans are often better at understanding the context of data. For instance, machine automation can be tripped up by subtle differences in, say, a customer address. |
Yes, this is a key obstacle to overcome. Let’s talk about how ML solves address and name issues.
First of all, what is an address? It’s not just a set of characters that can guide someone to your location. It can rely on interpretation by humans, too.

For example, let’s say I’m shipping a package to you, but I incorrectly write the street address — even though your name, city/state and postal code are correct. Well, you can almost guarantee my package will reach you because the delivery guy or gal knows your name and has delivered packages to your home before.
In short, no low-grade AI based system can achieve good matching of people with addresses. It requires much more system sophistication. You not only have to maintain the raw addresses, but also know the context of address: is it the shipping address or home address?
Additional databases need to be brought in so you more readily automate the matching of contextual information like a human can.
Right now, Mobileum uses 80 million language-labelled addresses for training. It’s very important to train the system to understand the wide variety of ways to specify an address.
Phonetic encoding is also key. The name Mary can be pronounced differently and there are algorithms that figure that out. And only after you get that phonetic input should you compare the name “Mary” with what’s on your black list.
Another vital aid is using collaborative data sources such as Google Maps. When you have the geo-location context, you can train your own machine learning model to deal with different variations of addresses much better.
| How does Mobileum actually implement a subscription fraud system at a telecom client? What does the basic process look like? |
We start by ingesting a wide range of data sets. The sources include the web, social profiles, leaked data about accounts. All of that information should be reaching your customer base, so when the customer arrives new to your platform, you already have a phone number or email reference. We also perform social crawling on the data the operator provides us.
We also obtain the ISP data and IP level of trust from the users arriving to your platform, and we use location based services, and analyze dealer transactions. Other possible sources are retail store data, partner’s data, micro-sites, email, mobile advertisements, and on-line ads.
The more data sources you have, the more accurate you will be.

So from the very beginning, then, as you ingest all these data sets, you already have strong evidence of who a particular person is. You can then use that info to compare against your black list.
In the end you make decisions based on the similarity of the data you have available. When you do that and you find someone on your black list, then you are doing artificial intelligence — mimicking how a human would think on solving this issue.
Taking the black-listed people on your list, we bounce that off our rules and machine learning models to give you a clear understanding if you face a fraud scenario and we can give you a near real-time deny decision.
And even if it’s not fraud, we have a capability to continuously monitor by opening a case to keep your fraud analyst informed over time.
And of course, we are assisting with the AI intelligence building. We don’t bring you a black box AI platform, but an explainable AI decision tool you can have confidence in.
| Is there a case showing how a subscription fraud solution can be integrated in a telco’s day-to-day operations? |
Yes, in fact, we recently published a case study of an operator in South Africa entitled, Detecting Subscription Fraud in an African Network Operator, and your readers are free to download a copy. The early results of this project show the magnitude of the problem. See the chart below.
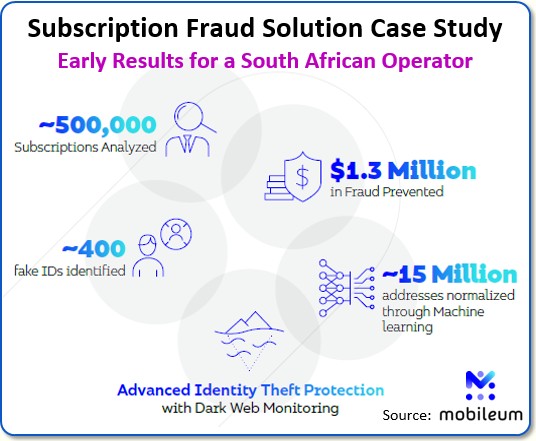
Our customer is a leading operator in Africa, providing a wide range of services, including data, mobile and fixed voice, messaging, financial services, Enterprise IT and converged services to over 40 million subscribers.
Mobileum’s fraud solution can actually be inserted in two ways into an operation:
- Post-Event Analytics of Fraud Cases to improve subscriber quality and
reduce fraud over time; or
- Integrated Real-Time in the Customer Onboarding Process — Subscribers
are scored to trigger several actions, such as: 1) requiring additional information,
2) validating an external channel (e.g. physical store, in case on IVR activations),
and/or 3) eventual blocking of the customer.
| Carlos, this is a great briefing. I certainly learned a lot about what’s happening in subscription fraud and the advantages that ML brings to the fight. |
My pleasure, Dan. We ran through a lot of topics. To get a better idea how Mobileum can help, I suggest your readers check out our web page on subscription fraud.
One issue that looms big on the subscription fraud problem is the rise of digital or on-line onboarding of subscriptions as opposed to in-store or face-to-face subscriptions.
Want to learn more about this threat? Then install a simple computer application, like THOR, on your laptop and you can access the deep or dark web.
If you search the dark web for “fake identity”, you will find opportunities to buy a fake identity by paying as little as $80 to $100. The buyer simply sends a photograph of themselves and gets an ID sent back with a fake identity.
Now lately, banks are opening up video chat to their onboarding process for new accounts, so you can imagine the security issues they will have if a fake ID can be used as part of a video-chat enabled registration.
At Mobileum we definitely see digital subscriptions as a very challenging security threat for telcos. Subscription fraud systems will be in great demand. And we’re working hard to support providers with full-blown systems that leverage multiple databases and algorithms trained by explainable AI with human expert guidance.
Copyright 2020 Black Swan Telecom Journal



Carlos Martins is the Head Of Engineering at Mobileum Risk Business Unit. Joining the company in 2012 to build a UX strategy, Carlos has more than 16 years of experience in the development and architecture of rich internet applications and SaaS products.
Currently leveraging Mobileum’s extended technology expertise, Carlos is leading the transformation project to evolve the company’s product portfolio toward public, private, and edge cloud architectures while also exploiting the latest AI/ML enhancements towards full 5G support.Ā
Recent Stories
- Epsilon’s Infiny NaaS Platform Brings Global Connection, Agility & Fast Provision for IoT, Clouds & Enterprises in Southeast Asia, China & Beyond — interview with Warren Aw , Epsilon
- PCCW Global: On Leveraging Global IoT Connectivity to Create Mission Critical Use Cases for Enterprises — interview with Craig Price , PCCW Global
- Subex Explains its IoT Security Research Methods: From Malware & Coding Analysis to Distribution & Bad Actor Tracking — interview with Kiran Zachariah , Subex
- Mobile Security Leverage: MNOs to Tool up with Distributed Security Services for Globally-Connected, Mission Critical IoT — interview with Jimmy Jones , Positive Technologies
- TEOCO Brings Bottom Line Savings & Efficiency to Inter-Carrier Billing and Accounting with Machine Learning & Contract Scanning — interview with Jacob Howell , TEOCO
- PRISM Report on IPRN Trends 2020: An Analysis of the Destinations Fraudsters Use in IRSF & Wangiri Attacks — interview with Colin Yates , Yates Consulting
- Telecom Identity Fraud 2020: A 36-Expert Analyst Report on Subscription Fraud, Identity, KYC and Security — by Dan Baker , TRI
- Tackling Telecoms Subscription Fraud in a Digital World — interview with Mel Prescott & Andy Procter , FICO
- How an Energized Antifraud System with SLAs & Revenue Share is Powering Business Growth at Wholesaler iBASIS — interview with Malick Aissi , iBASIS
- Mobileum Tackles Subscription Fraud and ID Spoofing with Machine Learning that is Explainable — interview with Carlos Martins , Mobileum